Outre sa capacité à couvrir des séquences beaucoup plus longues, le séquençage par nanopores détecte aussi les bases modifiées par méthylation, qui ne changent pas la séquence elle-même mais affectent la structure de l'ADN et l'expression des gènes. Des subtiles modifications épigénétiques qui ont des effets physiologiques chez les individus. « Nous commençons à découvrir que certaines des régions où il y avait des lacunes dans la séquence de référence sont en fait parmi les plus riches pour la variation des populations humaines, décrit Karen Miga. Il nous manque donc encore beaucoup d'informations importantes pour comprendre la biologie et les maladies. »
Après le chromosome X, l'équipe s'est attelée au séquençage des autres chromosomes. Mais cela risque de s'avérer un peu plus compliqué, notamment concernant les chromosomes acrocentriques (13, 14, 15, 21 et 22), qui ont un centromère très grand et donc beaucoup plus de répétitions.
A ce jour, il reste encore plusieurs chromosomes humains non entièrement décodés donc. En 2004, le chromosome 5 a été entièrement décodé, c'était le 12ème à l'être, sur les 24 types de chromosomes. Ce dernier ne présente pas moins de 180,9 millions de paires de bases pour 923 gènes, dont 66 sont connus pour être impliqués dans diverses pathologies, sans pour autant que l'on connaisse les mécanismes mis en jeu. Selon Spencer Abraham, secrétaire à l'Énergie américain, la connaissance de « cette séquence extrêmement précise sera à n'en pas douter un puissant outil dans la compréhension qu'ont les scientifiques des maladies affectant les êtres humains ». Sans savoir à quels gènes mutés les pathologies correspondent, la certitude est acquise que certains maux trouvent leur origine dans des altérations de gènes portés par le chromosome 5 : c'est le cas d'une certaine forme d'asthme, de la maladie de Crohn (une maladie du tube digestif qui peut entraîner un cancer), du syndrome de Sotos (un désordre mental) et de l'amyotrophie spinale notamment.
L'ADN "poupelle" ou "junk DNA" maintenant est en fait très important : sans lui, la cellule ne survie pas...
Si les sections codantes présentent un intérêt majeur, en particulier pour la médecine, celles qui ne codent pas ne sont pas pour autant en reste. En effet la comparaison de ces régions avec des portions génomiques d'autres espèces animales permet l'établissement de thèses nouvelles ou la confirmation d'anciennes, dans le domaine de l'évolution. Ainsi, une séquence présente sur le chromosome 5 se retrouve en tous points identique chez le chimpanzé, à ceci près qu'elle y figure inversée. Une modification de ce genre pourrait être à l'origine de la différenciation entre l'homme et le singe. Reste à comprendre la possibilité évolutive naturelle d'une inversion exacte de séquences précises pouvant donner par mutation une espèce complète distincte de la première. En fait, une telle manipulation pourrait tout aussi bien être artificielle et même faite de nos jours grâce aux instruments récemment inventés pour modifier l'ADN...
« L’ADN poubelle » ou « junk DNA », non codant pour des protéines, n’est définitivement pas dénué de fonction biologique. La compréhension de ces molécules est longtemps restée un défi, par manque de technologies permettant d’identifier l’ensemble de ces fonctions biologiques. Pourtant leur compréhension est bien cruciale alors que l’ADN non codant constitue la majeure partie, soit 98% du génome humain.
Au fil des études, l’ADN « poubelle » se révèle opérant dans de nombreux mécanismes, positifs ou négatifs, dont récemment le développement des tumeurs… Cette étude de l’Université du Michigan révèle ici un rôle positif de l'ADN satellite, un type de « junk DNA », dans la cohésion du génome. Des travaux présentés dans la revue eLife qui décrivent une nouvelle fonction biologique vitale qui consiste à s'assurer que les chromosomes se regroupent correctement dans le noyau de la cellule, un processus essentiel à la survie cellulaire.
L’étude est centrée sur l’ADN satellite péricentromérique constitué d'une séquence très simple et très répétitive de code génétique. Bien qu'il représente une partie substantielle de notre génome, l'ADN satellite ne contient pas non plus d'instructions codant pour la fabrication de protéines spécifiques. A ce titre, l’ADN satellite fait partie de « l’ADN poubelle ». Enfin, jusqu’à ces travaux on pensait que sa nature répétitive contribuait à rendre le génome moins stable et plus vulnérable aux dommages ou à la maladie. Il n’en est rien.
Tout d’abord, cet ADN ne pouvait être résumé à des déchets génomiques : Yukiko Yamashita, professeur au University of Michigan Life Sciences Institute et auteur principal de l'étude n’était pas tout à fait convaincus par l'idée que cet ADN se résumait à des déchets génomiques : « S’il ne nous est pas utile et s’il ne nous apporte aucun avantage, alors cet ADN aurait été effacé au cours de l’évolution ».
Ensuite, que se passerait-t-il sans cet ADN ? L’équipe a regardé ce qui se passerait si les cellules ne pouvaient pas utiliser cet ADN satellite péricentromérique. Comme cet ADN est constitué de longues séquences répétitives, les chercheurs ne pouvaient pas simplement muter ou couper l'ADN satellite entier du génome. Ils ont donc abordé la question via D1, une protéine connue pour se lier à l'ADN satellite. Les chercheurs ont ôté D1 des cellules d'un organisme modèle communément utilisé, la mouche à fruits (Drosophila melanogaster) et constaté alors que les cellules germinales - les cellules qui se transforment finalement en spermatozoïdes ou en œufs - étaient en train de mourir. Ces cellules mourantes formaient des micro-noyaux, ou de minuscules bourgeons, à l'extérieur du noyau qui comprenait des fragments du génome. Sans le génome entier encapsulé dans le noyau, les cellules ne pourraient pas survivre.
L'ADN satellite et la protéine D1 se lient en fait pour rassembler tous les chromosomes dans le noyau. Et si la protéine D1 ne peut se lier à l'ADN satellite, alors la cellule perd sa capacité à former un noyau complet et meurt. La protéine D1 a de multiples sites de liaison, de sorte qu'elle peut se lier sur plusieurs chromosomes et les emballer ensemble en un seul endroit, empêchant les chromosomes individuels de flotter hors du noyau. Des expériences similaires menées sur des cellules de souris aboutissent ici à de mêmes résultats.
Prises ensemble, ces données suggèrent que l'ADN satellite (qui fait partie de l'ADN "poubelle") est essentiel pour la survie cellulaire, et cela pour l’ensemble des espèces qui intègrent l'ADN dans le noyau cellulaire.
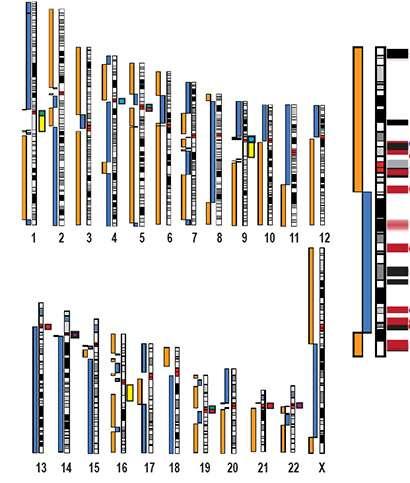
Chromosomes, les données : Chez l'humain, il existe 24 chromosomes différents : 22 chromosomes communs à l'homme et à la femme et 2 chromosomes sexuels, le chromosome X et le chromosome Y. Au final, chaque cellule humaine (non sexuelle) possède donc 23 paires de chromosomes. Les chromosomes humains ressemblent à des X avec deux bras courts et deux bras plus longs. La double hélice de l’ADN, une fois compactée, forme deux chromatides sœurs qui sont rattachées au niveau du centromère. Les extrémités du chromosome sont appelées télomères.

Le centromère peut se trouver exactement au centre des chromatides, presque au centre, être décalé vers l’extrémité des chromatides, ou très proche de l’un des deux télomères. Les chromosomes sont ainsi respectivement dénommés métacentrique, submétacentrique, acrocentriques ou télocentriques.
Le corps humain comporte 23 paires de chromosomes homologues :
- 22 paires de chromosomes autosomes, qui sont identiques chez l’homme et la femme, et numérotés de 1 à 22,
- 1 paire de chromosomes sexuels ou gonosomes X ou Y. La femme possède 2 chromosomes X alors que l’homme aura un chromosome X venant de sa mère et un chromosome Y venant de son père.
Les chromosomes sont dits homologues car ce sont deux lots identiques morphologiquement dont l’un vient de la mère et l’autre du père. La ploïdie désigne le lot de chromosomes venant de l’un des parents.
L’organisme humain est majoritairement formé de cellules diploïdes, qui ont deux jeux complets de chromosomes homologues et possèdent ainsi chaque gène en double exemplaire.
Le contraire de diploïde est haploïde. Les cellules germinales ou gamètes sont haploïdes, elles ne sont dotées que d’un seul jeu de chromosomes et donc d’un seul allèle de chaque gène.
On ne peut observer au microscope photonique les chromosomes dans cet état condensé que pendant la mitose ou la méiose. Le reste du temps, ils demeurent invisibles. En effet, les molécules d’ADN non condensées (la chromatine) se trouvent présentes sous forme diffuse dans le noyau des cellules.
 Les cellules sexuelles (ovule et spermatozoïde) sont haploïdes, elles ont 23 chromosomes. Après la fécondation, l’oeuf conserve un jeu de chromosomes apportés par chaque parent. Il en comptera 46 = 2 x 23 chromosomes. Ses cellules sont devenues diploïdes.
Les cellules sexuelles (ovule et spermatozoïde) sont haploïdes, elles ont 23 chromosomes. Après la fécondation, l’oeuf conserve un jeu de chromosomes apportés par chaque parent. Il en comptera 46 = 2 x 23 chromosomes. Ses cellules sont devenues diploïdes.
L’enjambement ou recombinaison intra-chromosomique
Durant chaque méiose, les chromosomes peuvent s’apparier de façon aléatoire et s’échanger des fragments de chromatide. Les gènes contenant les allèles paternels sont mélangés avec les gènes aux allèles maternels. Ce brassage intra-chromosomique est appelée enjambement (ou crossing-over).
Le réassortiment aléatoire ainsi que la recombinaison génétique des chromosomes d’un individu sont deux facteurs de la diversité biologique. C’est ce qui a permis l’évolution des espèces au cours des générations et leur adaptation à leur environnement.
Le Caryotype est propre à toute espèce :
Le nombre et la forme des chromosomes varient d’une espèce à l’autre. Le caryotype est un dessin ou une photographie de l’ensemble des chromosomes du noyau d’une cellule. L’ADN se trouve sous forme diffuse dans le noyau de la cellule, à l’exception du moment de la mitose ou méiose, où ils sont compactés. On injecte dans la cellule une substance qui interrompt la division, puis des colorants pour en faciliter l’observation. Le caryotype représente généralement les chromosomes bien alignés, classés selon leur forme et leur taille.

Présentation des 46 chromosomes après compactage dans le noyau et en caryotype
Au cœur de chaque cellule existent des chromosomes qui contiennent toute l’information nécessaire à sa fabrication et à son fonctionnement : l’information génétique. Les chromosomes sont formés d’un long polymère, l’ADN (abréviation d’acide désoxyribonucléique), où les nucléotides (molécules élémentaires) se succèdent à la manière de ces colliers de bonbons dont raffolent les enfants. Une tâche essentielle des biologistes pour étudier en profondeur un organisme vivant est d’obtenir la succession de nucléotides qui sont les perles d’information de ces énormes colliers d’ADN : on appelle cette tâche « séquencer » le génome de l’organisme. On séquence en général un mélange de génomes de plusieurs individus d’une même espèce. Pour l’espèce humaine, plus de 99,5 % du génome est commune à deux individus, le reste caractérisant nos différences visibles ou la plupart du temps invisibles et se traduisant par exemple en termes de susceptibilité à des maladies. Autrement dit, entre un pygmée africain de 1 m 50 et un norvégien de 2 m, il n'y a que 0,5 % de différence du point de vue génétique...
Depuis le premier génome entièrement séquencé en 1995, celui de la bactérie Haemophilus influenzae, l’exploration des génomes se poursuit de façon systématique. Les évolutions technologiques ont permis d’accroître dans des proportions importantes et à moindre coût la quantité et la fiabilité des données recueillies. Ainsi, on disposait en mai 2009 des génomes de près de 1 000 espèces différentes auxquels il faut ajouter des génomes de communautés microbiennes entières (sources hydrothermales, appareil digestif humain…).
Ce qui restait il y a quelques années un travail de bénédictin est maintenant largement automatisé, à l’aide d’outils mis au point par les bio-informaticiens. La vérification des résultats, elle, reste manuelle : après les annotations (ou interprétations) automatiques, des erreurs demeurent, qu’il faut traquer en recoupant différentes sources d’information. Une fois validées, les annotations sont organisées au sein de bases de données et normalisées pour permettre les comparaisons entre bases différentes. Enfin, pour faciliter les recherches scientifiques, elles sont rendues accessibles au moyen de navigateurs spécialisés.
La réalité des organismes supérieurs est plus complexe et en pratique il faut retrouver des gènes, non seulement très épars dans le génome, mais aussi morcelés en une mosaïque de fragments codants et non codants qui peuvent s’assembler de différentes manières, pour produire plusieurs protéines distinctes.
D’autre part, les séquences se ressemblent d’un organisme à l’autre, et ce d’autant plus qu’ils sont proches dans l’évolution. On repère 98 % de similarité entre l’homme et le chimpanzé ! On peut donc essayer de transposer les connaissances disponibles d’une espèce à une autre, même si celles-ci sont relativement éloignées. Ainsi, travailler sur le génome de la levure de boulanger permet aussi de comprendre le génome humain.
D’un point de vue informatique, retrouver des séquences qui se ressemblent implique des comparaisons de séquences et repose principalement sur ce qu’on appelle un « alignement ». Un alignement de séquences suppose que celles-ci sont des variations d’une même séquence d’origine (qu’avait par exemple un ancêtre commun) qui a été transformée. On peut imaginer ici chaque séquence comme une suite de perles colorées reliées par un fil élastique : un alignement consiste à tirer plus ou moins sur chaque élastique, de sorte que toutes les séquences soient de même longueur et qu’à chaque position, les perles soient de même couleur ou d’une couleur la plus similaire possible. Les molécules associées partagent des propriétés physicochimiques qui peuvent servir de base à cette comparaison. Chaque correspondance et chaque extension de fil nécessaire reçoit un score traduisant la similarité observée. La difficulté est de trouver la meilleure somme de scores possible par rapport à tous les alignements imaginables.
On dispose d’une méthode pour résoudre ce problème d’optimisation, la « programmation dynamique ». Celle-ci consiste à remplir une matrice de scores partiels dont le nombre de lignes et de colonnes est égal à la longueur des deux séquences à comparer. Mais une telle taille devient vite ingérable et il faut se contenter de méthodes moins précises mais plus rapides. Le logiciel le plus utilisé en bioinformatique, Blast, recherche au préalable des « graines », des mots qu’on peut retrouver à l’identique dans toutes les séquences à comparer. En effet, deux séquences proches ont forcément en commun des mots répétés.
Prenons une séquence constituée de 15 « A » successifs ayant subi 2 mutations au hasard : dans tous les cas, le mot « AAAAA » sera présent et on pourra trouver au moins 3 exemplaires distincts du mot « AAA ». Mieux, on peut même affirmer que la sous-séquence « AA ??A ??AA », où le « ? » indique un caractère quelconque, sera conservée. On se sert de ces mots facilement repérés et stockables dans un « dictionnaire » comme points d’ancrage pour des recherches plus complètes.
Cette idée de répétition correspond aussi à une réalité biologique : les génomes contiennent un nombre élevé de répétitions de types très variés. Celles-ci jouent un rôle majeur dans la structure, la fonction et l’évolution des génomes. Leur étude repose presque toujours sur la construction d’un dictionnaire de tous les mots présents dans la séquence étudiée. En pratique, les mots d’un génome entier peuvent ainsi tenir dans la mémoire d’un ordinateur. On peut ensuite modéliser la nature des répétitions. Dans tous les génomes, on observe des répétitions consécutives appelées « répétitions en tandem », dont on analyse la variation. Par exemple, on trouve sur notre chromosome X une suite de répétitions du triplet « CAG » de 9 à 32 fois dans le gène du récepteur aux androgènes (fixateurs d’hormones mâles). Lorsque le nombre de « CAG » dépasse 36, cela peut déclencher une maladie neurologique, la maladie de Kennedy. D’autres répétitions, les « transposons », sont capables de se déplacer et de se multiplier dans les génomes (elles forment 45 % du génome humain). En effet, le génome est une entité dynamique dont certains fragments vont s’autoexciser à certaines positions pour aller s’insérer ailleurs. Ces éléments mobiles expliquent la coloration surprenante de certaines plantes...
Tous les êtres vivants descendent d’une seule et même espèce vivante, une cellule originelle, apparue sur terre il y a environ 3,8 milliards d’années. Par « être vivant », il faut entendre « toute forme de vie ». Cet organisme formé dans l’eau des océans est à l’origine de l’entièreté de la biodiversité terrestre, c’est-à-dire qu’en prenant deux espèces au hasard, elles n’ont forcément fait qu’une, à un moment ou à un autre de leur évolution.
Par exemple, l’ancêtre commun entre l’homme et la levure a vécu il y a 2,5 milliards d’années; il en résulte 30% de gènes communs entre l’Homme et la levure aujourd’hui. Également, le dernier ancêtre commun entre l’Homme et le champignon existait il y a un peu moins de 700 millions d’années. Il n’y a que très peu de gènes qui sont uniquement propres à l’Homme...
Cette cellule originelle apparue sur Terre il y a environ 3,8 milliards d'années a donc trois possibilités pour son apparition : 100% locale (théorie de la "soupe primitive"), 100% extra-terrestre (théorie de la panspermie - apport via comètes et astéroïdes partout sur Terre) ou encore un mix des deux (briques d'ADN bien repérées dans les comètes et autres tombant dans une "soupe primitive" locale)... Autrement dit, en cas de panspermie (théorie qui commence à avoir plus de probabilités scientifiques que la simple "soupe primitive" de nos jours), l'ADN d'un organisme extra-terrestre pourrait très bien être assez similaire à celui trouvable sur la Terre, ou dans tous l'univers...
Les matières premières de la vie, y compris les atomes et les molécules organiques à partir desquels elle apparaît, se trouvent partout où nous regardons. Des composantes des météorites aux nuages de gaz présents dans l’espace, en passant par les disques protoplanétaires qui forment de nouvelles étoiles, la vie est partout. La question ne devrait pas être de savoir s’il y a de la vie dans l’Univers, mais comment nous allons la découvrir.
La différence entre un vivant terrestre et un vivant extraterrestre (même bactériel) ne pourra se faire éventuellement qu'au niveau "isotope", surtout si le principe de base est le carbone, comme nous.
En terme de recherche de vie extraterrestre, le plus difficile sera probablement… de la reconnaître en tant que telle lorsque nous l'aurons sous le nez. La plus grande partie de la vie sur Terre est microbienne, et bien que nous associons généralement les bactéries aux maladies, la plupart des espèces de bactéries ne présentent aucun danger pour l'humain. Certaines d'entre elles se développent dans des environnements où nous serions incapables de survivre, et vice versa : dans les profondeurs des océans, dans les grottes acides, dans la glace ou dans la lave. Pourtant, il y a bien une parenté entre ces organismes et nous, bien que le cours de l'évolution nous ait séparés.
En raison de cette parenté, toute vie sur Terre est construite à partir de cellules ; elle a besoin d'eau liquide pour persister ; elle est constituée à partir de molécules similaires contenant du carbone, de l'oxygène, de l'azote et quelques autres éléments communs ; enfin, elle utilise l'ADN et l'ARN pour coder des informations et les transmettre aux générations futures. Il faut pourtant se demander : pourrait-il en être autrement ? Si nous refaisions l'histoire de notre système solaire, la chimie de la vie serait-elle la même ? Évoluerait-elle de la même façon ? Pourrait-elle modifier son environnement de la même façon ? »
La vie est organique, ce qui signifie simplement qu'elle est à base de molécules contenant du carbone. Or, les molécules organiques sont très communes dans notre galaxie. Les astronomes ont identifié des acides aminés (les « briques » des protéines, en quelque sorte) sur des astéroïdes, et des bases azotées (les « lettres » génétiques de l'ADN et de l'ARN) dans des nuages de gaz à proximité d'étoiles. L'eau est nécessaire à la vie, et de fait, elle semble plutôt abondante dans l'univers.
Paradoxalement, la vie inorganique pourrait exister. « Organique » n'est pas synonyme de « vivant, » après tout. Le silicium se trouve dans la même colonne du tableau périodique que le carbone, puisqu'ils partagent de nombreuses propriétés. Ils ne s'apparient pas de la même façon aux autres atomes cependant, et ne forment pas les mêmes genres de molécules. Le carbone semble unique en son genre, puisqu'il est le seul à former des structures suffisamment complexes pour la vie... sur Terre.
L'ADN est en effet très, très complexe, ce qui amène les chercheurs à se demander comment et sous quelles contraintes il a pu apparaître en premier lieu. L'hypothèse la plus commune est que l'ARN, qui est constitué d'une seule chaine, par opposition à la double hélice de l'ADN, est apparu en premier. Cependant, l'ARN, lui aussi, est très complexe. « Peut-être que la vie n'a pas commencé avec l'ARN, mais avec une structure encore plus simple, » explique John Chaput de l'Université d'Arizona. « Quel qu'il soit, ce matériau a probablement contribué à former l'ARN. »
Le « D » de l'ADN et le « R » de l'ARN représentent les sucres désoxyribose et ribose, respectivement. Le désoxyribose et le ribose sont en quelque sorte les entretoises de l'échelle, tandis que les lettres génétiques en sont les barreaux. Cependant, celle-ci pourrait être construite avec d'autres sortes de sucres. Les molécules artificielles appelées « XNA » peuvent être construites à partir d'autres sucres : le X de XNA n'est ici qu'une possibilité parmi d'autres.
Chaput est plus particulièrement intéressé par un sucre connu sous le nom « thréose, » parce qu'il permet de former la molécule « TNA » qui « reconnaît » l'ARN et peut former des liens avec elle, tout comme l'ADN avec l'ARN. Le TNA est plus rudimentaire que l'ARN et l'ADN : sa structure est plus simple, et il est également plus facile à construire artificiellement. Chaput se demande si le TNA pourrait avoir servi de prologue à la vie sur Terre : « Parce que la TNA était plus simple à synthétiser, il est peut-être arrivé en premier, avant d'être supplanté par l'ARN. »
Les XNAs constituent potentiellement un chemin alternatif menant à la vie, mais ce n'est pas le seul. Le carbone permet de former beaucoup plus de types de molécules que la vie telle que nous la connaissons n'en emploie. Les protéines n'utilisent pas tous les acides aminés connus ; quant à l'ADN et l'ARN, ils n'exploitent pas toutes les bases azotées possibles. En cela, il pourrait exister d'autres formes de vie reposant sur la chimie du carbone, sur un code génétique, mais utilisant des molécules différentes pour construire leurs cellules. Toutes les formes de vie terrestres sont reliées les unes aux autres par un lointain ancêtre commun. Mais la vie telle que nous la connaissons a peut-être coexisté avec d'autres formes de vie non basées sur la chimie du carbone, il y a très longtemps.
Une chose intéressante est que les "briques" de la vie telle que nous la connaissons ont bel et bien été découvertes à la surface des comètes et à l'intérieur de météorites, et que ces "briques" extra-terrestres ont même été synthétisées artificiellement en 2016. Cela signifierait-il que, finalement, la vie telle que nous la connaissons soit universelle est pratiquement identique partout dans l'univers ? Des prélèvements sur un astre interstellaire en visite comme nous avons pu récemment en apercevoir serait important pour le savoir et augmenter les probabilités. Finalement, entre un être humain et un être du type ET comme dans le film du même titre, se pourrait-il qu'il n'y ait aussi que quelques pourcentages de différences génétiques "universelles" ?...
Sources : Miga, K.H., Koren, S., Rhie, A. et al. Telomere-to-telomere assembly of a complete human X chromosome. Nature (2020). https://www.nature.com/articles/s41586-020-2547-7
https://www.futura-sciences.com/sante/actualites/genetique-chromosome-humain-entierement-sequence-premiere-fois-4383/
https://www.futura-sciences.com/sante/actualites/genetique-genome-humain-cle-medecine-futur-integralement-sequence-1967/
https://www.santelog.com/actualites/adn-poubelle-sans-lui-point-de-survie-cellulaire
https://www.rd-mediation.fr/wp/2019/04/16/decoder-son-genome/
https://expertadn.fr/zoom-sur-le-chromosome-humain/
https://interstices.info/decoder-le-vivant/
https://www.vice.com/fr/article/4xnvng/saurions-nous-reconnaitre-un-extraterrestre-si-nous-en-voyions-un
https://www.forbes.fr/technologie/comment-trouver-des-preuves-dune-vie-extraterrestre/
https://www.ca-se-passe-la-haut.fr/2016/04/les-briques-de-ladn-synthetisees-partir.html
Compléments : https://www.sciences-faits-histoires.com/blog/ovni-ufo/adn-extra-terrestre-sur-terre-et-dans-l-homme.html
https://www.sciences-faits-histoires.com/blog/astronomie-espace/les-cometes-amenent-la-vie-partout.html
https://www.sciences-faits-histoires.com/blog/genetique-adn/briques-de-la-vie-du-ribose-dans-les-meteorites.html
Yves Herbo et Traductions, Sciences-Faits-Histoires, 19-07-2020